
Львиная доля обращений в техподдержку — это повторяющиеся вопросы: установка и активация модулей, типовые ошибки при настройке, параметры компонентов. Специалист снова и снова тратит время на запросы, которые решаются по одному и тому же сценарию, вместо того чтобы заниматься нестандартными задачами. Клиент при этом всё равно ждёт — не потому что вопрос сложный, а потому что очередь.
Это системная проблема, которая возникает в любой технической поддержке с ростом продукта. Мы в Сотбит с ней столкнулись и решили не нанимать людей под типовое, а разобраться с самим типовым. Итогом стал ИИ-ассистент Макс — сначала в тикет-системе, затем в онлайн-чате. Это кейс о том, как мы его строили: какую архитектуру выбрали, с чем столкнулись и как решали.
Разработка ИИ в России всё чаще уходит от демонстрационных чат-ботов к прикладным задачам — и техподдержка как раз из таких. Когда компания решает, кто занимается разработкой ИИ для конкретного процесса, выбор часто сводится к балансу между скоростью запуска и контролем над данными. Мы выбрали второе.
Почему не взяли готовое решение
Готовые ИИ-ассистенты для поддержки существуют — и мы их изучали. Но у большинства закрытая архитектура: данные клиентов уходят на сторонние серверы, а в тикетах регулярно встречаются персональные данные и техническая информация о конфигурациях. Отдавать это вовне — неприемлемо.
Второй момент — специфика. Готовые решения плохо гнутся под конкретный бизнес: нашу базу знаний, наши источники, нашу инфраструктуру. Коробочный бот не знает, как устроены компоненты наших модулей, какие ошибки возникают при конкретных настройках и что за ними стоит. Он будет давать обобщённые ответы в духе «проверьте документацию» — что хуже, чем вообще не отвечать.
Качество ответов напрямую зависит от базы знаний — а нашей базы нет ни в одном готовом решении. Источником должны быть реальные тикеты Сотбит: решённые кейсы, конкретные ошибки, проверенные шаги. Это нельзя компенсировать никакой тонкой настройкой чужой системы.
Разработка ИИ для бизнеса на собственном контуре — единственный вариант, когда в обращениях есть персональные данные и детали конфигураций клиентов. Вывод был однозначным: строим сами, на открытых инструментах, на собственном сервере. Для нас разработка ИИ в России с опорой на self-hosted инструменты — не идеология, а рабочая необходимость.
Архитектура: как это устроено
В основе — подход RAG (Retrieval-Augmented Generation). Принцип простой: модель не придумывает ответы из общих знаний, а сначала ищет релевантные фрагменты в базе и только потом формирует ответ на их основе. Для технической поддержки это принципиально — ответы должны быть точными, основанными на реальных кейсах Сотбит, а не на том, что модель «думает» про 1С-Битрикс в целом.
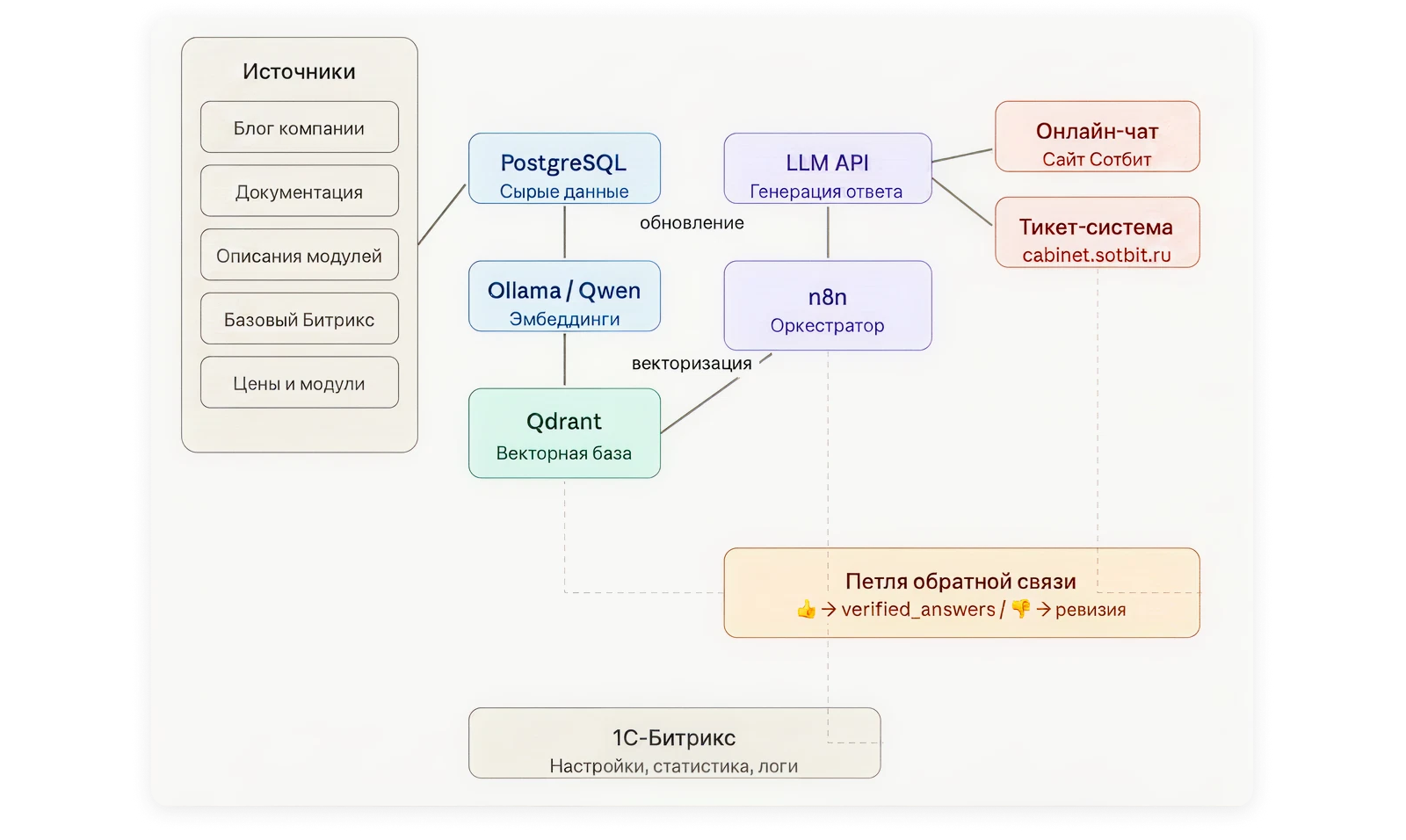
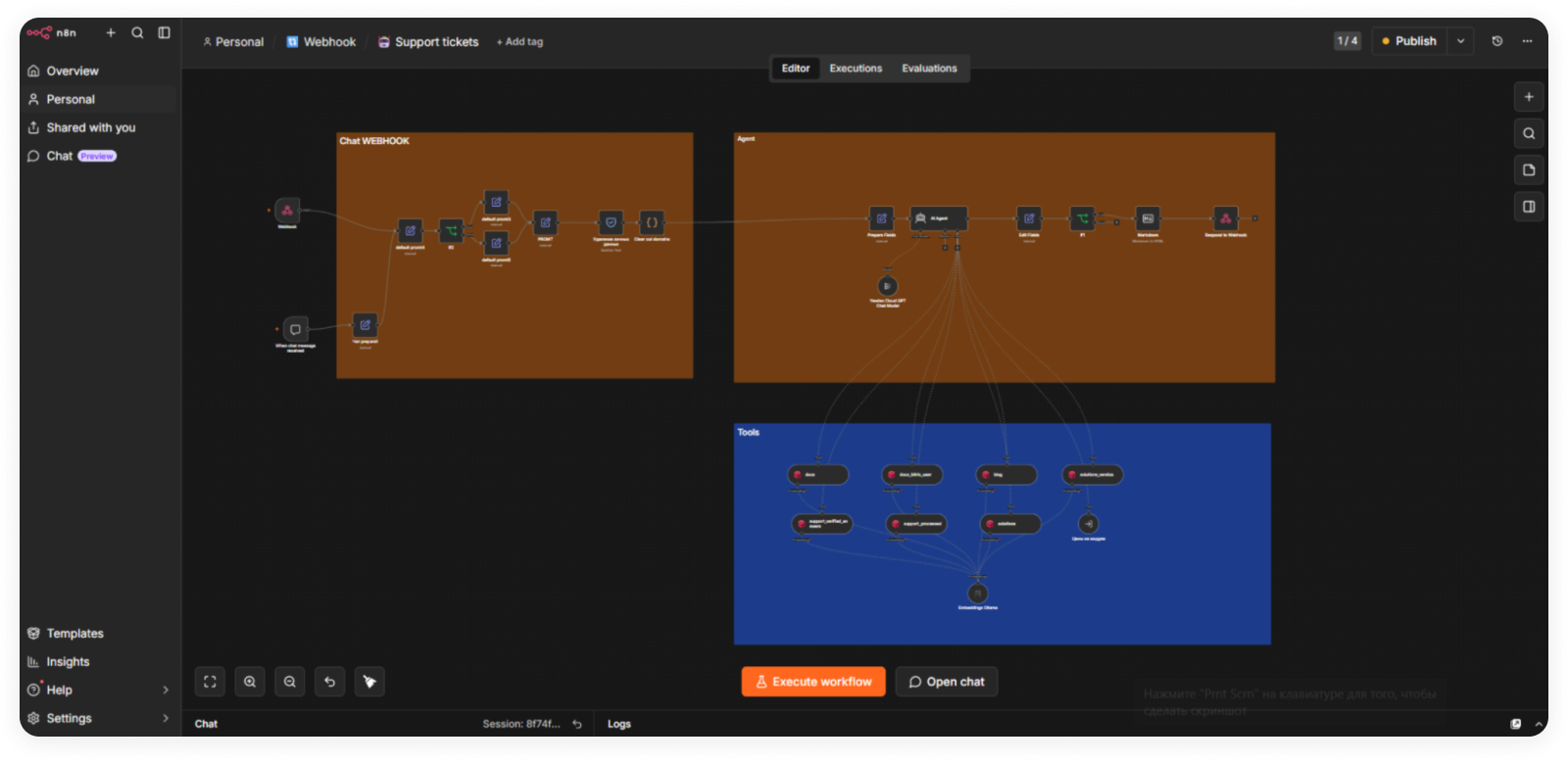
Все сервисы развёрнуты в Docker на собственном сервере. Оркестратором выбрали n8n — инструмент для визуального построения автоматизаций. Альтернативой была разработка на Python, но n8n позволил запустить первый прототип быстрее, наглядно видеть все процессы и редактировать их без кода. Плюс поддерживает большинство нужных интеграций из коробки — и данные никуда не уходят.
Хранение данных устроено в два слоя. Сырые данные живут в PostgreSQL — там удобно редактировать и обновлять информацию. При любом изменении таблицы n8n автоматически обновляет векторную базу в Qdrant. Векторная база хранит текст иначе, чем обычная: каждый фрагмент превращается в числовой вектор — эмбеддинг, — который отражает его смысл. Когда приходит вопрос, система ищет не по ключевым словам, а по смысловой близости: находит фрагменты, семантически похожие на запрос, даже если формулировка другая.
Эмбеддинги считаются локально через Ollama с моделью Qwen — данные не покидают контур. Стек ИИ российской разработки позволил держать этот этап внутри контура без передачи данных за рубеж. Итоговую генерацию ответа отдали внешнему LLM через API. Такой подход к разработке ИИ даёт контроль над каждым звеном пайплайна: от хранения до финального ответа клиенту.
|
Компонент |
Решение |
|
Оркестратор пайплайна |
n8n (self-hosted) |
|
Векторная база данных |
Qdrant (self-hosted) |
|
Хранение сырых данных |
PostgreSQL |
|
Эмбеддинги |
Ollama Qwen (local) |
|
Языковая модель |
LLM API |
|
Интеграция с тикетами |
1C-Bitrix → n8n |
База знаний: что внутри
Источников несколько: блог компании, документация по модулям, их описания, базовые материалы по 1С-Битрикс, актуальный прайс-лист. Отдельно — накопленный опыт из тикетов техподдержки за годы работы.
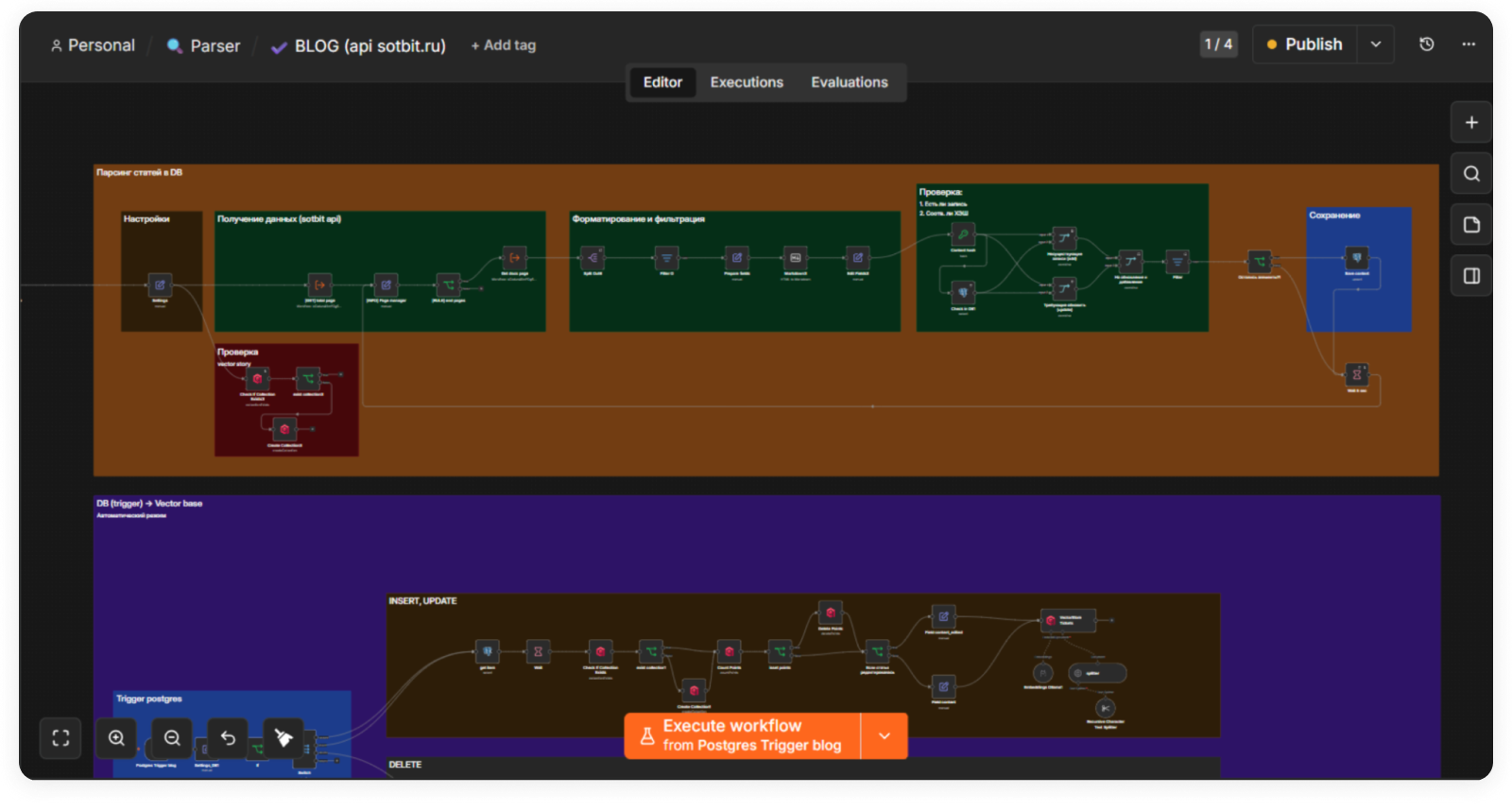
Сырые тикеты для базы не подходят: много воды, лишних деталей и персональных данных. Прежде чем попасть в систему, каждый тикет прошёл через локальную модель с промптом и правилами: убрать личные данные, имена, приветствия и шум, сделать выжимку в формате «вопрос — ответ». Такой формат дал наиболее точные результаты после нескольких экспериментов — модель находит нужное быстрее, когда не приходится пробираться сквозь «здравствуйте, спасибо за помощь».
Размер фрагментов для хранения тоже подбирали эмпирически. Остановились на 500 символах с перекрытием 200 символов. Перекрытие нужно, чтобы смысл не обрывался на границе: соседние куски слегка пересекаются, и контекст сохраняется. Именно этот размер дал наиболее точные ответы на практике.
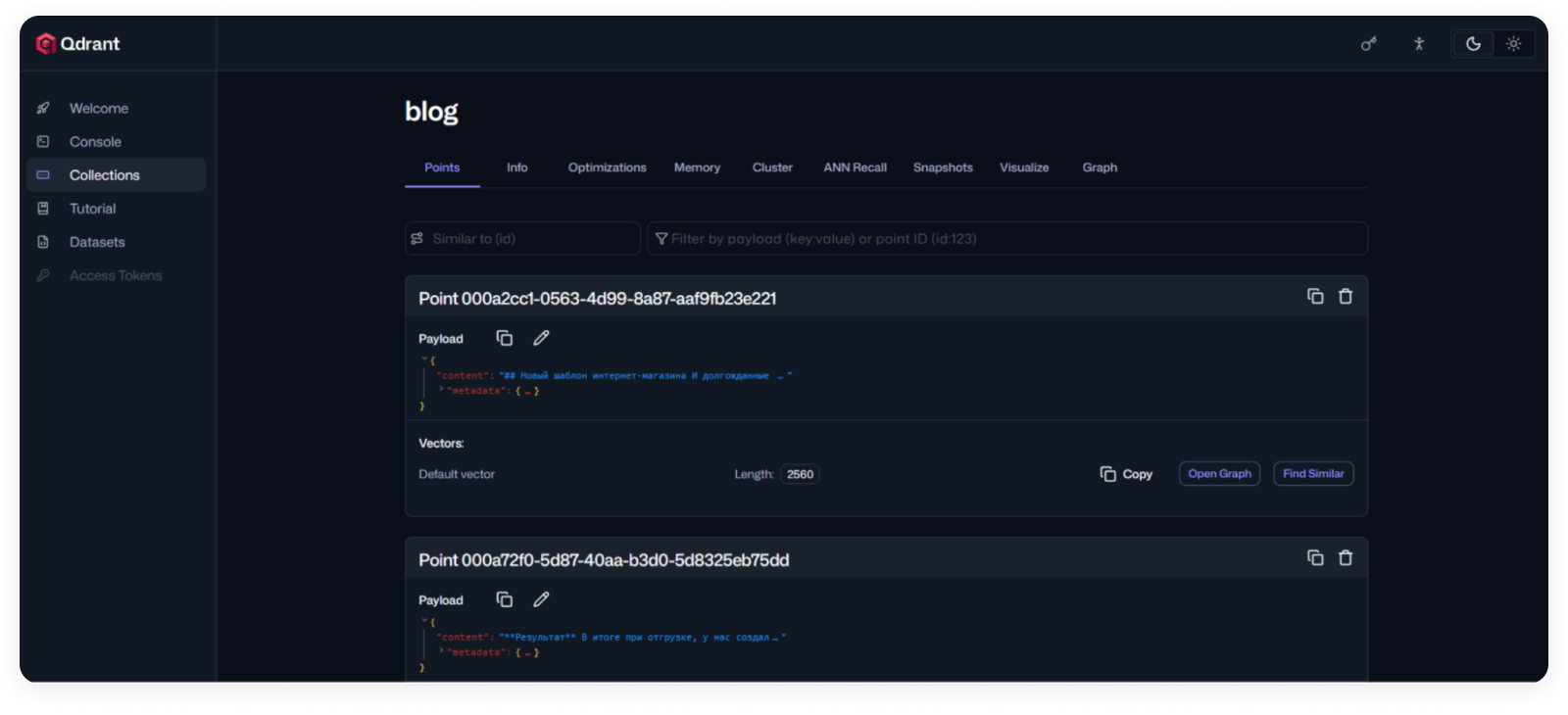
Внутри Qdrant — две отдельные коллекции. Первая, support_tickets, хранит обработанные тикеты в структурированном формате «Проблема / Причина / Решение / Теги». Вторая, verified_answers, — ответы, которые проверили живые специалисты поддержки. При каждом запросе сначала проверяется верифицированная коллекция: если совпадение выше порога 0.85 — ответ берётся оттуда. Проверенный специалистом ответ всегда приоритетнее автоматически обработанного тикета.
Выбор модели
Это заняло больше всего времени. Моделей много, и каждая ведёт себя по-разному: одна отвечает точнее, другая лучше держит контекст, третья галлюцинирует меньше. К каждой нужно подбирать параметры — например, температуру, которая регулирует, насколько «творческими» будут ответы. Для техподдержки нужна низкая температура: точность важнее разнообразия.
Начинали с лёгких локальных моделей — результат оказался неудовлетворительным. Ответы были поверхностными, модель плохо справлялась с техническими деталями и галлюцинировала уверенно — что для поддержки хуже, чем честное незнание. Для русского языка лучше всего показали себя модели ИИ российской разработки на базе Qwen и модели, обученные на русских датасетах. Чтобы не выбирать интуитивно, написали внутренние тесты: каждая модель прогонялась по одному набору вопросов из реальной базы, ответы сравнивались. Итоговая LLM — модель на 200+ миллиардов параметров с интеграцией по API. Качество ответов после перехода выросло принципиально.
Пайплайн обработки запроса
Каждый запрос проходит пять последовательных шагов — каждый с конкретной задачей и конкретным промптом.
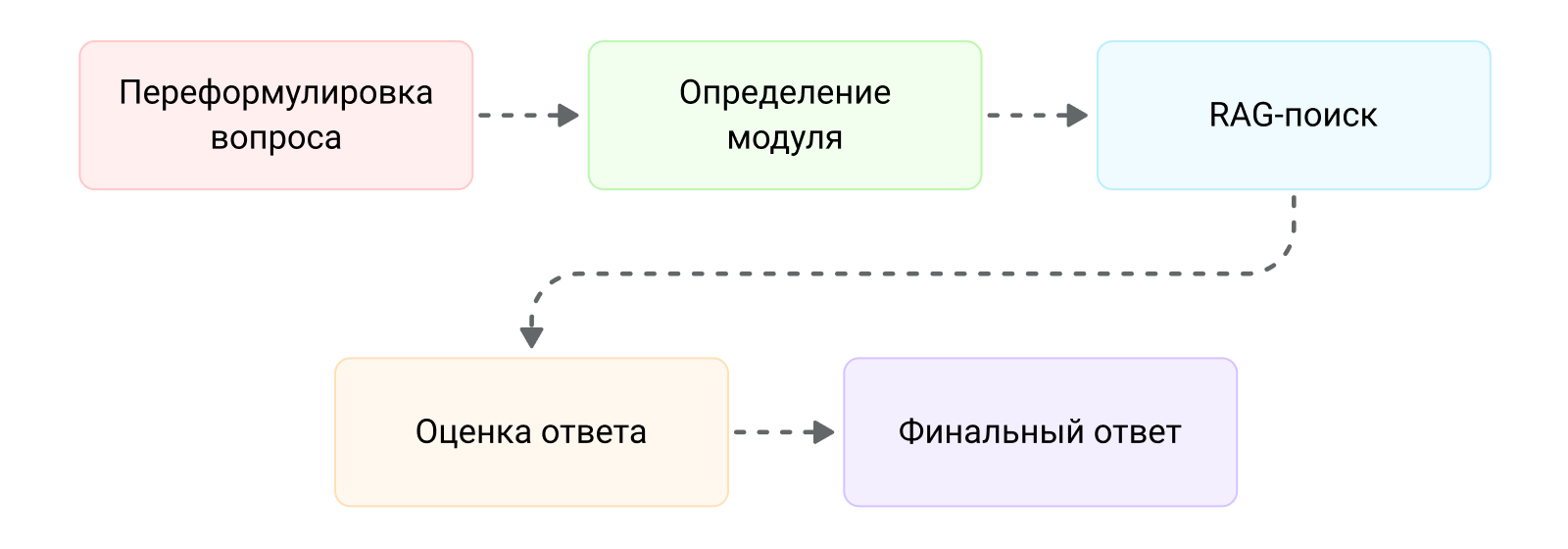
Переформулировка вопроса. Модель нормализует запрос, убирает опечатки, приводит к стандартной форме для векторного поиска. Клиент может написать «у меня не работает фильтр на странице каталога» — модель понимает, о чём речь, и ищет правильно.
Определение модуля. Классификатор определяет, к какому продукту Сотбит относится вопрос: B2B, Розница, Маркетплейс, SRM или модули. Это сужает область поиска и повышает точность.
RAG-поиск. Система ищет по обеим коллекциям, извлекает релевантные фрагменты и генерирует ответ на их основе.
Оценка ответа. Отдельная нода проверяет результат по трём критериям: релевантность вопросу, полнота ответа, источник информации. Нужен был не размытый «ответ вроде подходит», а чёткий бинарный результат: ПОЛОЖИТЕЛЬНО или ОТРИЦАТЕЛЬНО с указанием причины. Именно это стало ключом к надёжной фильтрации — следующая нода чётко понимает, что делать.
Финальный ответ. При положительной оценке клиент получает конкретный технический ответ. При отрицательной — честное «не нашёл» и ссылку на живого специалиста.
Такой пайплайн — типичный результат разработки ИИ решений для бизнеса, когда важна не только генерация ответа, но и проверка его качества до отправки клиенту.
Как это выглядит в работе
Онлайн-чат. Клиент открывает чат на сайте и задаёт вопрос. Макс отвечает мгновенно — приветственное сообщение сразу показывает, что это ИИ-ассистент, а не живой менеджер. Если в базе есть подходящий кейс — клиент получает конкретные шаги: какой файл, какой параметр, что изменить. Если базе не хватает информации — Макс честно говорит об этом и даёт ссылку на создание тикета. Клиент не получает правдоподобный, но нерабочий ответ.
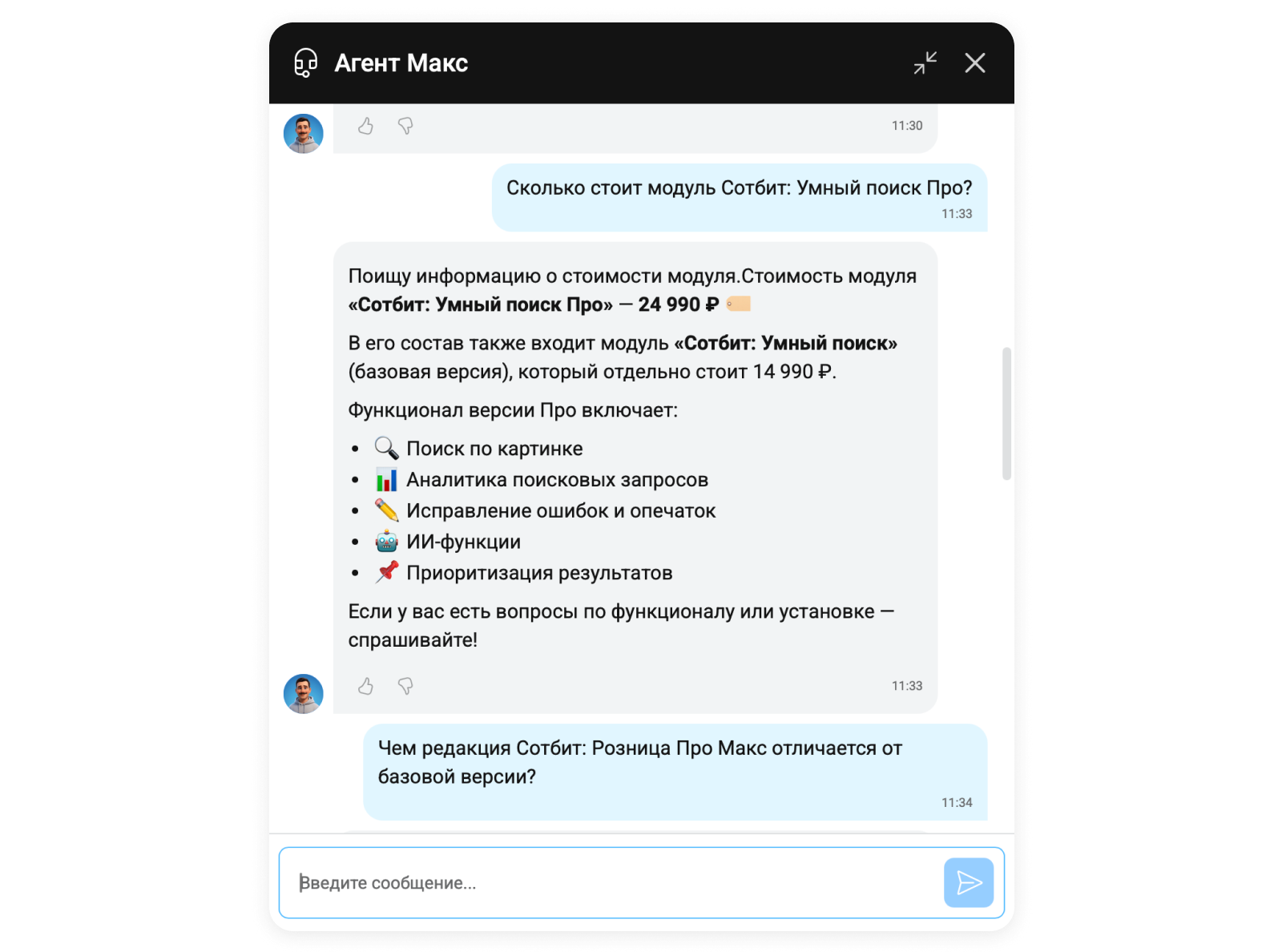
Тикет-система. Клиент создаёт тикет через cabinet.sotbit.ru. Система видит новое обращение и запускает пайплайн. Через несколько секунд внутри тикета появляется предложение ответа от Макса — только для специалиста поддержки, не для клиента. Специалист оценивает: если ответ точный — отправляет в один клик. Если нужна правка — корректирует и отправляет. Правильный ответ уходит в верифицированную коллекцию.
Эскалация. Происходит, когда бот получает оценку ОТРИЦАТЕЛЬНО — нет подходящего кейса в базе — или вопрос попадает в зону, где точность критична, а покрытие ещё недостаточное. В обоих случаях клиент получает честный ответ и понятный следующий шаг.
Что не работало с первого раза
Сервер падал на середине загрузки базы. При первой попытке загрузить тысячи тикетов в Qdrant система падала примерно на 89-м тикете — нагрузка на векторную базу без пауз между операциями. Решение: добавили Split In Batches по 20 тикетов и Wait ноду на 5–10 секунд между батчами. Загрузка стала занимать дольше, но проходила стабильно. Параллельно нашли и исправили нюанс в JS-коде внутри n8n, который давал некорректные результаты при определённых форматах входных данных.
Модель «думала вслух». При первых тестах Макс выводил внутренний монолог прямо в ответ клиенту — что-то вроде «итак, мне нужно найти подходящий кейс, проверю сначала верифицированную коллекцию...». Решение: добавили постобработку, которая вырезает всё, что похоже на внутренние рассуждения. После этого модель начала сразу выдавать финальный результат.
Первая база оказалась «пустой». Когда загрузили тикеты как сырые диалоги, система получала тексты вида «здравствуйте / пришлите доступы / спасибо, вопрос решён». Технической сути ноль. Переработали промпт извлечения: каждый тикет теперь преобразуется в структурированный чанк с точным текстом ошибки, диагнозом и шагами решения. Тикеты без технического содержания отфильтровываются автоматически ещё на этапе загрузки.
Оценщик давал размытые результаты. Первая версия промпта выдавала «ответ частично подходит, но может потребовать уточнений» — следующая нода не понимала, что с этим делать. Переписали под строгий формат: только ПОЛОЖИТЕЛЬНО или ОТРИЦАТЕЛЬНО, плюс причина по каждому из трёх критериев. После этого логика эскалации заработала надёжно.
Галлюцинации на редких вопросах. Когда в базе не было похожего кейса, модель начинала придумывать: называть несуществующие параметры, предлагать шаги, которых нет в системе. Боролись комплексно: явный запрет в промпте («не выдумывай решений, которых нет в контексте»), поле НАЙДЕНО: да/нет как сигнал для следующей ноды, отдельная проверка поля ИСТОЧНИК в оценщике. При отсутствии ответа в базе система теперь честно признаёт это.
Как система учится в процессе работы
После каждого ответа специалист ставит оценку. Если ответ понравился — он автоматически через n8n попадает в коллекцию verified_answers и начинает влиять на следующие похожие запросы. Если нет — специалист разбирает случай вручную: правит инструкцию модели, удаляет устаревшую информацию или добавляет правильный ответ в базу напрямую.
Все процессы отслеживаются в n8n: при ошибке приходит автоматическое уведомление. Ключевые настройки вынесены в отдельный модуль внутри 1С-Битрикс — там же собирается статистика запусков и полный лог. Редактировать параметры можно без разработчика.
При выборе стека мы опирались на инструменты ИИ российской разработки — они лучше справляются с русскоязычной техподдержкой и не требуют отправки данных за рубеж на этапе эмбеддинга.
Выводы
Макс работает на двух каналах: онлайн-чат на сайте и тикет-система cabinet.sotbit.ru. Первая линия типовых вопросов закрывается автоматически — специалисты переключились на нетиповые задачи: интеграции, сложные конфигурации, кейсы, где нужна экспертиза, а не поиск по базе.
Клиент получает первый ответ мгновенно. Если ответ точный — вопрос закрыт без участия человека. Если нет — к специалисту придет уже обогащённый тикет. Это само по себе ускоряет разбор.
База знаний из разрозненных тикетов превратилась в структурированную систему. Знания команды перестали быть привязаны к конкретным людям — новый сотрудник может опереться на неё при онбординге, а не разбираться методом проб неделями. Система продолжает обучаться: чем дольше работает, тем точнее отвечает на похожие вопросы.
Разработка ИИ решений для бизнеса на заказ — не про демо-ботов, а про задачи с измеримым эффектом: скорость ответа, разгрузка первой линии, структурирование знаний. Разработка ИИ для бизнеса в сегменте техподдержки особенно окупается там, где типовых обращений много, а экспертиза команды дороже времени ожидания клиента. На рынке работают компании занимающиеся разработкой ИИ в Москве и в других регионах — чаще всего они тоже начинают с узкого кейса, и наш проект подтверждает этот подход. Разработка ИИ в России при этом всё чаще строится на открытых инструментах и собственной инфраструктуре. Типовой сценарий разработки ИИ на заказ — от аудита обращений до пилота на одном канале, и только потом масштабирование.
Следующий шаг — расширение покрытия редких сценариев и улучшение качества ответов. О результатах расскажем отдельно.
Если планируете строить что-то похожее — надеемся, этот разбор сэкономит время на старте. Либо обратитесь в Сотбит: поможем внедрить ИИ-ассистента под вашу задачу.



